mysql 知识点
环境准备 - 环境配置与校验 - docker-compose 启动 - 命令行连接 -  - 自检命令 - 版本、用户、数据库 -  - 字符集 -  - 时区 -  - 当前 sql_mode -  - 建库建表 - 建库 -  - 建表 - 插入数据 -  - 查/改/删 -  - 导入导出 - 导出(逻辑备份) -  - 导入 - mysql -h 127.0.0.1 -P 3306 -u root -p demo < demo.sql - 仅导出表结构 - mysqldump -h 127.0.0.1 -P 3306 -u root -p --no-data demo > demo_schema.sql - 账号与权限 - 创建业务账号 (最小权限) -  - 查看权限 -  基础查询 - 基础查询 - 电商数据集 - 单表查询 - 查询最近注册的 20 个用户 -  -  - 查询 Tokoyo 的用户列表,按注册时间排序 -  -  - 查询 email 以 @test.com 结尾的用户 -  -  - 查询注册时间在某区间的用户数 -  -  - 查询 city 为空的用户 -  -  - 查询价格在 [100,300] 的商品,按照 price 排序 -  -  - 查询每个 category 下价格最高的商品,并列最高 -  -  - 查询 paid/done 订单表,按照 created_at 倒序分页 (page=3, size=10 => offset = 1) -  -  - 查询某用户 user_id = 1 最近 10 笔订单 -  -  - 查询取消订单 status = 4 中 total_amount > 500 的订单 -  -  - 查询订单总额 top20,只统计 paid/done -  -  - 查询今天创建的订单 -  -  - 查询最近 30 天内创建但未支付 status = 0 的订单 -  -  - 查询商品名称包含 pro 的商品(不区分大小写) -  -  - 查询用户表中名称重复的用户 -  - 聚合统计与报表 - 用户总数、订单总数、已支付订单数 -  -  - 每个城市用户数 -  -  - 每个 category:商品数、均价、最高、最低 -  -  - 每种订单状态的订单数 -  -  - 最近 7 天每天订单数 -  -  - 最近 7 天每天 GMV -  -  - 每个用户订单数 & 总消费 -  -  - 每个用户最近 30 天订单数 & 消费 -  -  - 订单数 >= 2 的用户 -  -  - 累计消费 >= 2000 的用户 -  - 每个用户客单价 AOV (paid/done) -  -  - 每个 category :销量 & 销售额 -  -  - 每个商品销售额 top20 -  -  - 每个用户买过的不同商品数 -  -  - 每个城市 GMV -  -  - 本月新增注册用户数 -  -  - 复购用户数 -  - JOIN 查询 - 订单列表:订单 id、用户 + 订单 + 明细 -  -  - 每个订单:商品件数 & 商品种类数 -  -  - 每个用户最近一笔订单时间 -  - 每个用户最近一步订单:订单号 + 金额 -  -  - 从未下单的用户 -  - 从未支付过订单的用户 -  - 订单总额与明细汇总不一样的订单 -  - 每个用户最常购买的品类,返回按购买次数排序的 top1,并列会多行 -  - 每个用户买过的商品清单,去重商品名 -  - 用户画像,用户 id、城市、订单数、总消费、最近下单时间 -  - 沉睡用户:注册 > 30 天,且最近 30 天无订单 -  - 子查询 - 有订单的用户 -  - 订单金额 > 全站平均订单金额 -  - 用户消费金额 > 全站平均消费金额 -  - 每个品类价格最高的商品 -  - 至少买过 2 个不同品类的用户 -  - 买过品类 A 但是没有买过品类 B 的用户 -  - 首单金额 >= 500 的用户 -  - 存在异常订单的用户(金额不一致) -  - 用户订单间隔 > 60 天 -  - 未支付订单占比高的:未支付/总单数 > 0.5 -  - CASE WHEN 与常用函数 - 订单状态码转中文文案 -  - 订单金额分层统计 -  -  - 用户城市空值归一:NULL/空串 -> UNKNONW,统计城市分布 -  - 本月到今天 GMV -  - 每个用户注册至首单的天数 -  - 提取邮箱并统计各域名用户数 (@ 后面的部分) -  - 生成脱敏邮箱:前缀保留前 2 位,其余用 ***,再拼回域名 -  - 最近 7 天每天新增付费用户数 -  - 常见坑点 - NULL 判断不能用 = - COUNT(col) 不会统计 NULL - WHERE 和 HAVING 的过滤时机不同 - LEFT JOIN + WHERE right.col = 会变 left join 为 inner join - IN 包含 NULL 导致 NOT IN 结果异常,建议用 NOT EXISTS - DISTINCT 是对整行去重,不是对某列去重 约束与范式基础 - 约束与范式基础 - 约束 - 目的 - 保证数据一致性 - 让错误尽早暴露 - PRIMARY KEY (主键) - 保证 - 唯一性:表内每行有唯一标识 - 非空性:主键列不能为 NULL - InnoDB 聚簇索引 - UNIQUE (唯一约束) - 保证 - 某列会某族列的值不能重复 - 本质会创建一个唯一索引 - 示例 -  - MySQL 的 UNIQUE 允许多个 NULL,因为 NULL 不等于 NULL - FOREIGN KEY (外键约束,InnoDB 支持,慎用) - 保证 - 子表引用的父键必须存在 - delete/update 时可以配置联动行为 - 优点 - 数据一致性强 - 代价 - 写入路径变重 - 锁和死锁更复杂 - 历史脏数据不好修复 - 跨库不可用 - NOT NULL (非空) - 范式 - 依赖/函数依赖(functional dependency) - 在一张表中,如果确定一组列 X 的值,就能唯一确定另一列 Y 的值,那么 Y 依赖于 X,记作 X -> Y - 目的 - 用一套可检验的规则来设计表结构,使得数据依赖关系放对地方,避免“冗余、不一致、异常操作“三类问题。 - 更新异常 - 同一事实在多处重复,更新要改多行,多处改漏就不一致 - 插入异常 - 插入某类信息,因为表结构耦合,要插入不该填的信息 - 删除异常 - 删除某类记录时,不小心删除本应该保留的数据 - 1NF (原子性) - 列不可再分 - 反例 - user_phone="138,139,140" 多值 - 2NF (消除针对主键的部分依赖) - 针对联合主键的表 - 如果表用 (order_id,product_id) 做联合主键,那么 product_name 不能放在这个表里 - 3NF (消除传递依赖) - 字段不要依赖非主键字段 - 用户表存了 city_id,又存了 cit_name,city_name 依赖 city_id,理论应该拆到 city 表 - 反范式(违反 3NF) - 为了性能/查询便利 - orders 冗余 user_name 快照 - 冗余的是快照字段,而不是事实字段 - 事实字段在主表,订单里的是下单当时的快照 索引 + EXPLAIN - 索引 + EXPLAIN - 准备索引 -  - 覆盖索引 + 回表 - 聚簇索引 - 在 InnoDB 中,主键索引就是聚簇索引,表的数据行存放在 B+Tree 的叶子节点上,并且物理组织顺序按主键排序 - PRIMARY KEY 不仅仅是纯逻辑约束,还决定了数据的物理布局 - 主键越大、越随机,写入越容易导致页分裂 - 二级索引 - 二级索引 B+Tree 的叶子节点保存的不是整行数据,而是 (user_id, created_at, PRIMARY_KEY_VALUE) - 二级索引带着主键,但是不带其他列 - 回表 - SQL 命中二级索引时 - 先在二级索引树里定位到符合条件的条目 - 拿到这些条目的主键 id - 如果查询需要整行或者非索引列,就需要再用主键去聚簇索引里取行数据,这就是回表 - 时机 - 使用二级索引过滤/排序,但是 SELECT 的列不在索引里,就会回表 - 代价 - 结果行很多时,会变成大量随机 I/O,把一次索引扫描变成大量主键点查 - 覆盖索引 - 如果一个查询所需要的列都包含在某个二级索引里,引擎只读索引即可返回结果,无需回表 - EXPLAIN 查看覆盖索引 - Extra:Using index 表示只用索引就能满足查询列,结合 type/key/rows 判断是否想要查询的覆盖索引 - 实验 - EXPLAIN -  -  -  -  - 两条都可能用 key=idx_user_cnt,第一条更容易出现 Extra: Using index (覆盖索引) - 使用 EXPLAIN ANALYZE 看实际的执行效果会更直观 -  -  -  -  - actual time/rows:第二条通常更慢 - loops:多次取行 - 覆盖索引升级:把查询列塞进索引 - idx_user_cnt 也能覆盖 id,因为二级索引叶子也包含主键 id -  -  - 单列索引 vs 联合索引 - 单列索引的劣势 -  - idx_user 能够快速定位符合条件的集合 - 这些订单在索引里按照 user_id 分组,组内不保证按照 created_at 排序 - 为了排序,需要先取出数据,再做排序 (Using filesort),最后再取前 20 - 联合索引的优势:变排序为索引顺序扫描 - CREATE INDEX idx_user_ct ON orders(user_id, created_at); - 执行逻辑:先定位到 user_id=123 的区间,再在这个区间按照 create_at 顺序向后扫描,扫到 20 条就停 - 联合索引顺序 (a,b,c) - 等值过滤列 (=/IN 选择性高) - 排序列 (ORDER BY/BETWEEN/>=) - 实验 - 清理环境 - SHOW INDEX FROM orders; - ALTER TABLE orders DROP INDEX idx_user_ct; - 只有单列索引 -  - 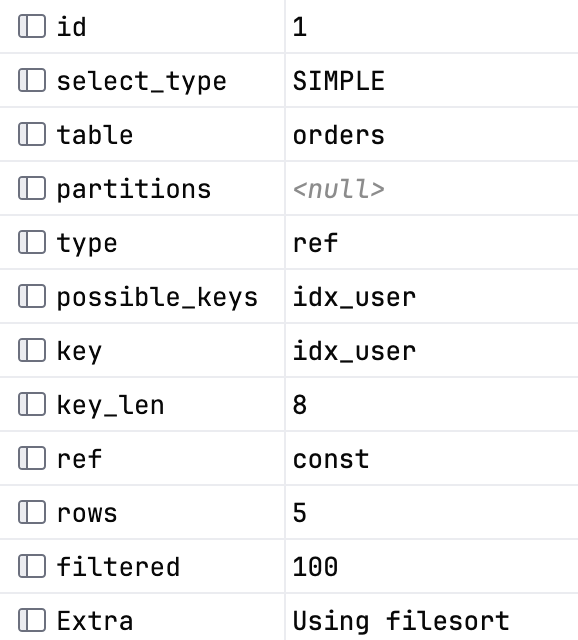 - Extra: Using filesort - row:通常偏大 - 加上联合索引 -  - Extra:filesort 消失,包含 Using index,rows 通常更小 - 最左前缀 + 范围条件 - 最左前缀 - 对于联合索引 (a,b,c),Mysql 可以高效使用 (a) (a,b) (a,b,c) 而不能高效使用 b、c 和 b、c - 等值匹配 vs 范围匹配 - 等值:=、IN(...) - 范围:> >= < <= BETWEEN LIKE 'prefix%' - 联合索引能够向右继续使用下一列,需要前面的列是等值匹配 - 实验 - 命中最左前缀(只用 user_id) -  -  - 等值 + 范围 -  - 只有 created_at (最左前缀缺失) -  -  - key = NULL / type = ALL - key_len 判断索引使用了几列 - 联合索引的 key_len 会变小 - 排序优化 (Using filesort 的消除) - Using filesort 含义 - MySQL 不能直接按照索引顺序输出结果,需要额外排序 - 排序可能在内存完成,内存不足才会落盘成临时文件 - 是性能风险信号,排序行数越大越危险 - ORDER BY 能否走索引排序的判定条件 - ORDER BY 的列序必须匹配索引前缀 - 索引是 (a,b),ORDER BY a,ORDER BY a,b 可以满足 - WHERE 的过滤要让排序区间连续 - WHERE a = 常量,ORDER BY b - 排序方向要一致 - ORDER BY created_at DESC - 实验 - 观察 filesort -  -  - 建立匹配索引,消除 filesort -  -  - GroupBy 与临时表 - GROUP BY 策略 - Sorting Aggregation (排序聚合) - 先把数据按 group ky 排序 - 再顺序扫描,连续相同 key 的行聚合 - 如果排序不能通过索引完成,可能出现 Using filesort - Hash aggregation - 用哈希表按 group key 存聚合状态 - 一边扫描一边更新聚合值 - 哈希表大/需要落盘中间结果 -> 出现 Using temporary - Using temporary - 在 Extra 中看到 Using temporary 表示 MySQL 需要创建临时表来保存中间结果。 - 临时表可能存在内存,也可能落盘 - 触发条件 - GROUP BY 的 key 无法直接利用索引顺序 - 同时有 GROUP BY,order by 与 group by 不一致 - 分组结果集很大 - 选择了很多列 - 实验 - 按照用户统计付费订单数与 GMV - 典型报表 -  -  - Using temporary 几乎必现 - Using filesort 也很常见 - 函数分组 -  - DATE(created_at) 对列做函数,会让 idx_ct(created_at) 很难直接用于分组有序输出,通常会扫描大量行 + 临时表 + 排序/哈希 - 使用索引改善 GROUP BY - GROUP BY 很难做到完全不 temporary - 减少扫描行数 (rows) - 让过滤走索引 - 尽量用窄表/覆盖减少回表与临时表宽度 - 索引失效 - 对索引列做函数 - B+Tree 的定位能力被破坏 - B+Tree 索引快是能对原始列值做范围定位 - 写成:WHERE DATE(created_at) = '2026-02-13' 索引里面存的是完整的 create_at 值,对它做了 DATE() 变化,很难精确映射到索引的连续区间 - 反例 -  -  - 正例 -  -  - 隐式类型转换 - EXPLAIN SELECT * FROM orders WHERE user_id = '123'; - EXPLAIN SELECT * FROM orders WHERE user_id = 123; - LIKE - B+Tree 只能做前缀有界范围 - 'Phone%' 等价一个范围,有连续区间 - '%Pro%' 无法形成连续区间 - OR、NOT、!=、NOT IN - OR 导致优化器放弃单一路径,建议改成 UNION ALL 两段 - !=、NOT 选择性差,扫描大 - EXPLAIN - type (引擎如何找数据),从好到差: - const/system:通过主键或唯一索引直接定位到一行 - ref:用非唯一索引的等值匹配,返回一组行 - range:索引范围扫描,BETWEEN、>=、LIKE - index:全索引扫描,把整棵索引从头扫到尾 - ALL:全表扫描 - key/possible_keys:为什么选择这个索引 - possible_keys:优化器认为可能有用的索引集合 - key:最终选择的索引 - rows/filtered:一眼估算工作量 - rows:优化器估算要读多少行,越大越危险。不是精确值,但是可以判断是否值得优化 - filtered:估算过滤后能留下多少百分比,越小代表过滤越强 - rows * filtered% = 经过 where 过滤后剩余行数 - Extra:性能信号灯(最重要) - Using Where - 表示存储引擎返回行后,SQL 层还需要再做 WHERE 过滤 - 很常见,不一定坏 - 坏的情况:Using where + rows 很大,说明扫很多再过滤 - Using index (覆盖索引) - 表示只用索引就能拿到所有的查询列 - 常用于:只查索引列 + 主键 - 一般是好信号,要结合 Type - ref/range + Using index:常见的高效覆盖 - index + Using index:可能是全索引扫描 - Using filesort(额外排序) - 不利用索引完成 ORDER BY,需要额外排序步骤 - 排序量大可能落盘,速度慢 - Using temporary (临时表) - GROUP BY/DISTINCT/复杂排序 需要临时表存中间结果 - 可能内存,可能落盘(数据大) - Using index condition (ICP 索引条件下推) - 把部分过滤下推到存储引擎层,在扫描索引时就过滤一部分 - 不等于覆盖索引,仍然可能回表 - 索引条件下推 - 把原本回表后需要在 Server 层做的过滤,尽可能提前到存储引擎层,在扫描二级索引时就过滤掉一些不满足条件的记录 - JOIN 与驱动表选择 - MySQL 优化器通常选择“成本更低“的表做驱动表(先过滤更强的) - 驱动表过滤越强越好,被驱动表必须有匹配索引(join key) - JOIN 优化 = 选对驱动表 + 给被驱动表 join key 索引。 - 深分页 OFFSET 优化 - OFFSET 本质:先找到前 1000 行再丢弃掉,成本随着 offset 线性增长 - KeySet:用上次最后一条记录的排序键继续查 - 游标分页 -  事务与并发控制 - 事务与并发控制 - ACID - A 原子性:要么全成功,要么全失败,依靠 undo log + 回滚机制 - C 一致性:约束/规则不被破坏 - I 隔离性:并发事务互不干扰到你能接受的程度 - D 持久性:提交后不丢(redo log + 刷盘策略 + 崩溃恢复) - autocommit - autocommit=1 默认 - SELECT @@autocommit - 每一条 DML 语句执行完成都会自动提交 - autocommit=0 - 会话级:需要手动 COMMIT/ROLLBACK - 容易造成忘记提交的长事务 - SET SESSION autocommit = 0; - 一致性视图 - 一致性读 - 普通 SELECT (不带锁子句) 是一致性读 - 不加锁(不阻塞别人写),读到的是某一个一致性快照上的数据 - 好处:读并发极高 - 代价:读到的可能不是最新提交的值 - 锁定读 - SELECT ... FOR UPDATE (排他锁) - SELECT ... LOCK IN SHARE MODE (共享锁) - 会对读到的记录加锁,会阻塞其他事务对这些记录的写 - 实验 - 数据准备 -  - autocommit=1 下,一条 UPDATE 自动提交 - SessionA - UPDATE tx_demo SET val = val + 1 WHERE id = 1; - SessionB - SELECT val FROM tx_demo WHERE id = 1; - SessionB 立刻看到 + 1 后的值 - 显示事务 + ROLLBACK - SessionA -  - SessionB - SELECT val FROM tx_demo WHERE id = 1; - A 在事务内能看到更新后的值 - B 在 A 未提交前看不到变化 - A rollback 后,变化消失,所有会话回到原值 - Commit 的可见性 - Session A -  - Session B - SELECT val FROM tx_demo WHERE id = 1; - Commit 后 B 才能看到新值 - 一致性读 + 锁定读 - Session A (不提交) -  - Session B - UPDATE tx_demo SET val = val + 1 WHERE id = 1; -- 这里会阻塞等待锁 - Session A 把 FOR UPDATE 换成普通 SELECT -  - Session B 不会被 A 的普通 SELECT 阻塞 - 普通 SELECT 不会挡住别人的 UPDATE (MVCC) - FOR UPDATE 会挡住别人的UPDATE (行锁) - 隔离级别与三大现象 - 4 级隔离: -  - 实验 - 数据准备 -  - 脏读 - SessionA -  - SessionB -  - Session A 再次读到 - RU:A 可能读到 999 - RC/RR:A 不会读到 999 - 不可重复读 - 同一事务中,两次读取同一行,结果不同(因为其他事务提交了更新) - SessionA -  - SessionB -  - SESSIONA 再次读 - RC:A 第二次读到 222 - RR:A 第二次读到 200 - 幻读 - 同一事务,两次按照同一条件查询,返回的行集合不同(因为别的事务插入/删除了符合条件的行) - SessionA -  - SessionB -  - RR 下前后两次读到的都是 2 - RC 下前第一次读到 2,第二次读到了 3 - 锁定读 FOR UPDATE 与 next-key lock - SessionA -  - SessionB -  - RR + For Update:B 的插入会被阻塞,被 A 的 next-key lock 挡住 - RC 下 FOR Update 的锁范围更小,不一定锁 GAP。 - 结论 - RU 几乎不用:会出现脏读,业务不可接受 - RC 会出现可重复读/幻读,但是并发更松,锁冲突相对较少 - RR 一致性读更稳定:同一事务多次读结果一致 - MVCC(版本链 + Read View) - InnoDB 里面一条记录行在并发更新下会形成版本链 - 当前记录页里保存的是最新版本(Latest Committed 或未提交版本) - 旧版本信息存在 undo log 里面,通过指针串起来(版本链) - 每个版本都有创建它的事务标识:trx_id(以及用于回滚/版本回溯的指针) - Read View:决定你对这个事务能看见哪些版本 - 做快照读时(普通 SELECT),InnoDB 会用一个 Read View 来做可见性判断。 - 对于某条记录的某个版本(由 trx_id 标识): - 如果这个版本是你自己事务写的 -> 可见 - 如果创建该版本的事务在你创建 Read View 时已提交 -> 可见 - 如果创建该版本的事务在你 Read View 时仍未提交(或之后才开始)-> 不可见 -> InnoDB 会沿着 undo 版本回溯,找到一个可见的旧版本。 - RC 与 RR 的关键差异:Read View 的生命周期 - RR:同一事务内的快照读通常复用同一个 Read View -> 两次普通 SELECT 结果一致 - RC:每条语句的快照读都可能生成新的 Read View(语句级一致性)-> 第二次 SELECT 可能看到别的事务提交的新数据 - 快照读 vs 当前读 - 快照读 - 普通 SELECT - 用 Read View + undo 回溯读旧版本 - 通常不加行锁 -> 读不阻塞写,写不阻塞读 - 当前读 - SELECT ... FOR UPDATE - SELECT ... LOCK IN SHARE MODE - UPDATE/DELET - 这些需要读取当前最新且可用于修改/锁定的版本,并对记录/范围加锁 - 当前读不是靠 MVCC 保证一致,是通过锁 - 实验 - 创建表 -  - RR 下的可重复读 - SessionA -  - SessionB -  - B 的提交产生了新版本,但是 A 的 ReadView 让它不可见,于是回溯到 v=100 - 当前读会阻塞 (FOR UPDATE) - SessionA -  - SessionB -  - FORUPDATE 是当前读 + 加锁,阻塞并发写,不走 MVCC 的无锁读 - MVCC 的工程代价 - 长事务会让旧版本无法清理 - 高频更新会制造大量版本 - 行锁结构(Record/Gap/Next-Key) - 锁的位置:索引 - InnoDB 的行锁不是锁表的行号,而是锁索引记录和索引记录之间的间隙 - 三种锁的定义 - Record Lock (记录锁) - 锁住某个具体索引记录 - 典型:按主键/唯一索引等值锁定一行 - 影响:阻塞别人对该记录的 UPDATE/DELETE - Gap Lock(间隙锁) - 锁住索引记录之间的空档范围 - 作用:阻止别人往这个 Gap 里 INSERT 新记录 - 常见于 RR 下的范围锁定读/范围更新 - Next-Key Lock(临建锁) - = Record Lock + Gap Lock - 锁住某条索引记录以及它前面的 Gap - 什么时候出现哪种锁 - 等值命中 主键/唯一索引 - SELECT * FROM t WHERE id = 10 FOR UPDATE; - 通常只需要 Record Lock - 唯一性保证不可能插入另一个 id=10,没必要锁 Gap - 等值命中 非唯一索引 - SELECT * FROM t WHERE k = 10 FOR UPDATE; -- k 是普通索引 - 可能对 k=10 对应的一组索引记录加锁 - 同时可能涉及 next-key/gap 防止插入新的 k=10 造成集合变化 - 范围查询 - SELECT * FROM t WHERE k BETWEEN 10 AND 20 FOR UPDATE; - RR 下通常会对索引 k 的范围加 next-key(覆盖整个区间) - 锁定义语义 - FOR UPDATE(排他锁 X) - 语义:我接下来要修改这些记录,不允许别人并发改/删/锁定 - 会阻塞: - 别人对同一记录的 UPDATE/DELETE - 别人对同一记录的 SELECT ... FOR UPDATE - 在 RR 下,可能阻塞落在同一范围的 INSERT(gap/next-key) - 典型场景 - 扣库存 - 余额扣减 - 状态机推进 - LOCK IN SHARE MODE - 我希望别人不要修改这些记录,但是允许别人也读 - 会阻塞: - 别人对同一记录的 UPDATE/DELETE(写需要 X 锁,与 S 冲突) - 允许别人 SELECT/SELECT ... LOCK IN SHARE MODE - 不建议这样写,建议直接用 FOR UPDATE - 丢失更新与两种解决方案(乐观/悲观) - 丢失更新:两个并发事务基于同一个旧值做读-改-写,后提交的覆盖先提交的写,导致先提交的修改丢失了 - 错误写法 - SELECT stock FROM products WHERE id = 1; 读到 10 - 应用层算出 new_stock = 10 - 3 = 7 - UPDATE products SET stock = 7 WHERE id = 1; - 两个事务同时做,会把其中一个扣减覆盖掉 - 解决方案 1:悲观锁 - 不相信并发环境下别人不会动它,先把行锁住,再读再改写 - 乐观锁 - 我允许并发发生,但提交更新时必须检测数据没人改过,否则失败重试 - 版本号乐观锁(CAS 思路) - 条件更新(无显示 version,适合库存/额度) - 死锁与锁等待排查 - 锁等待 - 表现:某条语句一直卡住(直到超时) - 原因:要的锁被别人持有,只能等 - 结果:最终等到锁释放成功,要么超时失败 - 参数:innodb_lock_wait_timeout,默认 50s - 死锁 - 表现:两(或多)个事务形成循环等待,A 等 B 的锁,B 等 A 的锁 - InnoDB 会主动检测并选择一个事务回滚 - 故障排查 SOP - 用 data_lock_waits 找 blocking_pid - 用 data_locks 看锁类型/索引/是否 GAP - 用 innodb status 还原死锁链路或等待细节 - 找谁挡谁 -  - waiting_pid:卡住的那条 SQL - blocking_pid:真正的持锁者 - blocking_sql:它在做什么 - 到底等什么的锁 -  - INDEX_NAME:锁在哪个索引,PRIMARY 还是某个二级索引 - LOCK_MODE:是否包含 GAP - LOCK_STATUS:WAITING/GRANTED - InnoDB Status:死锁/等待的人话版证据 - SHOW ENGINE INNODB STATUS - LATEST DETECTED DEADLOCK:最近一次死锁的完整链路,SQL、索引、锁类型 - TRANSACTIONS:当前锁等待 - Processlist:快速识别 MDL/DDL - SHOW PROCESSLIST; - Waiting for table metadata lock -> 多半是 DDL 或者是长事务 MDL - 实验 - 准备表 -  - 死锁类型 A:加锁顺序不一致 - SessionA -  - SessionB -  - 预期:其中一个会话报 deadlock 并回滚 - 下单事务边界设计(订单+明细+库存+支付状态) - 典型下单链路与拆分原则 - 本地事务:创建订单 + 明细 + 预扣/冻结库存 - 事务外:调用支付(或下游) - 本地事务:处理支付回调(幂等)+推进订单状态+扣减冻结/确认库存 - 订单状态机 - 最小状态集 - CREATED:订单已创建 - PENDING_PAYMENT:等待支付 - PAID:支付成功 - CANCELLED:取消/超时取消 - REFUNDED:已退款 - 关键约束:状态推进必须单向并且有条件 - PENDING_PAYMENT -> PAID - PENDING_PAYMENT -> CANCELLED - PAID -> REFUND - 三种库存策略 - 直接扣减 - 下单时直接 stock = stock - n - 风险:支付失败要补偿(回滚库存),需要可靠的取消/超时机制。 - 冻结库存 - 库存分为 - available_stock 可售 - frozen_stock 冻结(锁定给待支付订单) - 下单 available -= n,frozen += n - 支付成功 frozen -= n (确认出库) - 取消/超时:available += n,frozen -= n - 库存流水 - 用流水记录变更,按流水聚合库存 - 适合强一致性审计,但是实现复杂,读性能压力高(需要物化) - 事务边界设计 - 下单:创建订单+明细+冻结库存 - 幂等键:idempotency_key (来自客户端/业务生成),订单表加唯一约束) - 事务内步骤 - 插入订单 - 插入订单明细 - 冻结库存 - 示例 -  - 调用支付(事务外) - 事务提交后,再调用: - 支付下单 api - 生成支付链接 - 为什么在事务外 - 支付调用可能慢/失败/重试 - 事务内长期持有锁、占连接、阻塞其他订单和库存写,放大锁等待与死锁 - 支付回调(本地事务 2):幂等落库+状态推进+确认库存 -  - 订单超时取消(本地事务 3):状态推进+释放冻结 -  - 事务日志(redo/undo/binlog)与两阶段提交(2PC) - redo/undo/binlog - redo:InnoDB,物理页级,WAL - 解决:持久性 + 崩溃恢复 - 记录对数据页做了什么修改,更偏物理意义,用于崩溃后重放到数据页 - 采用 WAL(Write-Ahead Logging):先写日志,再异步刷脏页 - 即使数据页还没刷盘,只要 redo 持久化,崩溃后也能恢复 - 简单理解:数据库修改先写在便签(redo),再慢慢抄到大账本(数据页)。 - undo log:InnoDB,逻辑回滚信息 + 旧版本 - 解决:原子性 + MVCC - 回滚:事务失败时,按 undo 把修改撤销 - MVCC:提供旧版本,让快照读能读到“过去的值“ - 代价:长事务会让 undo 堆积 - binlog(MySQL Server 层,逻辑日志) - 解决:复制(主从)+点时间恢复(PITR)+ 审计 - 记录逻辑事件:如“某表插入了哪些行/执行了什么语句“ - 不属于 InnoDB,而是 MySQL Server 层统一管理 - 主从复制依赖 binlog(从库拉取并重放) - 为什么 redo 不等于 binlog:解决的是不同问题 -  - 两阶段提交 (2PC):保证 redo 与 binlog 同生共死 - 核心问题:提交时要同时写 redo 和 binlog,如果写到一半崩溃,会出现灾难性不一致 - 只写了 redo,没写 binlog: - 主库崩溃恢复后数据存在,但从库永远看不到(复制丢事务) - 只写了 binlog,没写 redo: - 主库崩溃恢复后数据不存在,但从库重放后出现 - MySQL 用 2PC 把 redo 与 binlog 的提交绑定在一起 - 关键流程 - 事务准备阶段(Prepare) - InnoDB 写 redo log prepare(表示:我已经把这个事务的 redo 记录齐了,处于可提交状态) - 写 binlog - Server 层把该事务写入 binlog(并根据配置决定是否 fsync) - 提交阶段(Commit) - InnoDB 写 redo log commit(表示事务正式提交) - 崩溃恢复判定规则 - 有 prepare 无 commit:看 binlog 是否存在该事务;存在补 commit,否则回滚 - 有 commit:一定提交(重放 redo) - 关键可靠性参数 - innodb_flush_log_at_trx_commit:控制 redo 的刷盘策略 - 1(最安全):每次提交都把 redo 刷盘(fsync) - 2:每次提交写到 OS cache,每秒 fsync(可能丢失 1s 事务) - 0:每秒写 + 刷(风险更大) - sync_binlog:控制 binlog 的刷盘策略 - 1 (最安全):每次提交都 fsync binlog。 - 0:由 OS 决定何时刷(可能丢) - 长事务危害与治理 - 长事务 - 事务持续时间长 - 事务持有锁很久 - 事务一直没有结果 - 危害 - undo 膨胀 + MVCC 历史版本堆积 - 锁等待/吞吐下降 - 死锁概率上升 - MDL 阻塞 DDL/DML - 复制延迟 - 自增锁/热点资源争用加剧 - 备份/一致性快照变慢或变大 - 定位长事务 - 查看当前正在跑的会话 - SHOW PROCESSLIST; - Time 很大 - State 出现 Locked/Waiting for ... lock/Waiting for table metadata lock - 直接找活的最久的事务 -  - trx_age_sec 最大的 - trx_state 是否 RUNNING/LOCK WAIT - trx_query 在做什么 - 精准定位谁在等谁 -  - 查看锁明细 - SHOW ENGINE INNODB STATUS - 止血:如何让系统恢复 - 让持锁事务提交/回滚 - KILL 持锁连接 - 缩短等待 - 如果是 MDL 卡住,定位 DDL/持锁事务,结束它们,避免高峰 DDL - 制度化 - 应用层硬约束 - 事务内禁止外部调用 - 事务内只做:必要的几条 SQL - 所有事务用 try { ...; commit } catch { rollback } finally { cleanup } - 连接池必须保证 - 出错时 rollback - 归还连接前清理会话状态 - 设置超时 - 业务接口超时 - DB 侧锁等待超时策略 - 批处理/大事务拆分 - 错误示例:UPDATE t SET ... WHERE created_at < '...'; - 按照主键或时间分片,分批提交 - DDL 发布规范 - 高峰期不做 DDL - 选择 online DDL 能力 - 先建索引再切流,或者用灰度策略 - 对 "Waiting for table metadata lock" 设置报警 - 监控报警 - information_schema.innodb_trx 种 trx_age 超阈值数量 - 锁等待数量/时间 - undo 表空间增长 - 复制延迟 表设计与数据治理 - 表设计与数据治理 - 建模方法与边界 - 建模方法 - 列出核心用例 - 查询(读):用户订单列表、订单详情、支付结果、库存可售、待支付超时扫描。 - 命令(写):创建订单、锁/冻结库存、支付回调、取消订单、发货。 - 抽实体与关系 - 订单 - 订单明细 - 库存 - 支付交易/回调 - 事件/审计 - 定边界 - 哪些字段属于状态(可覆盖可更新) - 哪些属于事件/流水(只追加不更新) - 哪些属于派生/统计(可重建,允许异步) - 边界划分 - 状态表 - 特点:一行代表一个业务对象的当前状态,会被更新 - 示例 orders - status、paid_at、cancelled_at 这写会变 - 读多写少,但是必须写正确(条件更新/事务) - 适用于需要当前值的读 - 事件表 - 特点:只追加,不覆盖;用于审计、追溯、重放。 - 示例 order_events - 记录状态变迁:PENDING -> PAID,以及时间、操作者、来源 - 永远不 UPDATE,只 INSERT - 适用 - 查发生过什么 - 重建派生数据 - 流水表 - 特点:和事件表很像,更偏可对账、可汇总 - inventory_ledger、payment_txn - 每次扣减,冻结,释放都记录一条流水 - 可做对账:库存表 = 初始 + 流水汇总 - 适用:资金/库存这种需要强审计的域 - 聚合表 - 特点:为查询加速而存在,可异步更新,可重建 - user_order_summary,daily_gmv - 允许最终一致 - 目标让核心查询不扫大表 - 边界经验 - 状态表保证在线业务 - 时间流水表保证可追溯与对账 - 聚合表保证性能与体验 - 电商“订单-库存-支付“ - 建议最小表集 - orders:订单状态表 - order_iterms:订单明细 1-N - inventory:库存状态表 - payment_notify 或 paymenet_txn:支付回调/交易流水 - order_events:订单事件表 - 边界怎么定 - 订单当前状态只在 orders,不要在多张表复制写 - 所有发生过的动作进 order_events(可追溯) - 支付回调必须有独立表 + 唯一约束做幂等(不要只靠 orders) - 库存推荐冻结模型:inventory.available/frozen,支付成功/取消再结算 - 主键设计 - InnoDB 的数据行物理组织顺序就是主键顺序 - 主键越短越好:二级索引都要携带主键值 - 主键越递增越好:写入更顺序,减少页分裂与随机 I/O - 主键一旦选错很难改 - 主键方案 - 自增 BIGING(最常用,默认推荐) - 雪花/时间有序 ID(推荐的分布式主键) - UUID (不推荐当主键) - 业务号 (一般不建议) - 字段类型与表达 - 字段类型选型 - 金额 - DECIMAL(18,2) - 金额最小货币单位方案:用 BIGINT 存分/厘,但要统一单位与换算 - 对账/财务更偏 DECIMAL - 时间 - DATETIME(3):推荐默认(毫秒精度,语义不依赖死区转换) - TIMESTAMP(3):会受 session 时区影响,范围更小 - 业务事件时间(下单时间、支付时间):优先 DATETIME(3) - 需要跟 UTC/时区联动的场景才考虑 TIMESTAMP - 列表分页建议 ORDER BY created_at DESC, id DESC - 状态/枚举 - TINYINT/SMALLINT 存 code - 代码层映射枚举 - 字符串与文本 - VARCHAR - 适合短文本:订单号、手机号、渠道、外部交易号 - 可建索引、可唯一约束 - TEXT/BLOB - 适合长文本:备注、富文本、日志原文 - TEXT 不能有默认值 - 需要检索的长文本:用搜索引擎倒排,不能指望 MySQL 上做 LIKE 全文 - JSON - 适合 payload/扩展字段 - 不适合高频过滤/排序字段 - JSON 里需要检索的 key 提取成独立列并建索引 - Boolean - MySQL 没有真正 boolean,常用 TINYINT(1) 或者 BIT(1) - 工程上,推荐 TINYINT(1) NOT NULL DEFAULT 0 - NULL 策略 - 建议尽量 NOT NULL - NULL 引入三值逻辑:=,<> 的行为让过滤结果看起来怪 - 统计聚合、唯一约束语义、索引选择也更复杂 - 三值逻辑 - col = NULL 永远为 NULL(不是 true) - 判断 NULL:必须 IS NULL/IS NOT NULL - 字符集与排序规则 - 全库统一 utf8mb4 - 排序规则要统一、可预测 - 表达层面:默认值、精度、约束、生成列 - 默认值 - 时间戳列:created_at/updated_at 建议在应用层写入或触发器默认值策略统一 - 唯一约束与幂等设计 - 唯一约束 - 保证在表内某个键组合只出现一次,是数据层的硬规则,不依赖应用正确性 - 适用:唯一表示、去重、幂等落库的最终防线 - 优点:并发下天然正确 - 幂等 - 保证同一请求执行多次,结果与执行一次等价 - 三要素 - 如何识别同一请求 - 重复请求如何处理 - 副作用怎么避免重复 - 幂等写入的 4 种标准写法 - INSERT ... ON DUPLICATE KEY UPDATE - 第一次插入,第二次则更新某些字段 - INSERT IGNORE - 重复就忽略,不需要更新 - 条件更新(状态机幂等) - 先插流水再改状态 - 软删、审计与可追溯 - 审计字段设计 - created_at DATETIME(3) NOT NULL - updated_at DATETIME(3) NOT NULL - created_by BIGINT NULL (或 NOT NULL + 0) - updated_by BIGINT NULL - created_from VARCHAR(32) NULL (来源:WEB/APP/ADMIN/JOB) - updated_from VARCHAR(32) NULL - 软删除 - 典型软删字段 - is_deleted TINYINT(1) NOT NULL DEFAULT 0 - deleted_at DATETIME(3) NULL - deleted_by BIGINT NULL - delete_reason VARCHAR(64) NULL - 为什么要软删 - 合规与可追溯:能恢复、可审计 - 避免误删不可逆 - 支持撤销/恢复业务 - 状态表 + 事件表 - 仅靠 updated_at 不够,真正追溯需要事件表 - 状态表(当前态) - 事件表(历史轨迹) - order_id - event_type - event_at - operator_id - source - payload - 归档、冷热分离与保留策略 - 归档:把低频/历史数据搬离在线库 - 原因 - 表越来越大 -> 索引越来越大 -> buffer pool 命中下降 -> 查询变慢 - 索引膨胀 -> 写入/更新维护成本变高 -> TPS 下降 - 备份窗口变长、DDL 变更风险大 - 冷数据占用昂贵的 SSD,成本不划算 - 技术手段 - 归档到历史表 - orders(热) + orders_archive(冷) - 分区 - PARTITION BY RANGE (TO_DAYS(created_at)),按月/周分区 - 冷库(另一个 MySQL 实例) - 对象存储/数仓(S3/OSS + Parquet 或 Clickhouse) - 历史明细导出到对象存储,提供离线查询 - 变更与在线 DDL - MDL:MySQL 对表加 Metadata Lock 来保证 DDL 与 DML 的一致性。 运维与排障 - 运维与排障 - 指标体系 - 指标分层 - 业务层(用户感知层) - QPS:每秒 SQL 请求数 - TPS:每秒事务提交数(更接近写负载与提交压力) - RT(P95/P99):请求响应时间分位数:95%/99% 的请求在这个时间内完成。 - 错误率:SQL 执行失败的比例与类型 - 慢查询数量/慢查询占比:超过 long_query_time 的语句数量 (slow log) - 连接与线程层指标 - Threads_connected(当前连接数):当前已建立的客户端连接数量 - Threads_running(正在执行的线程数):正在执行的线程连接数 - max_connections 使用率:Threads_connected/max_connections - InnoDB 引擎层指标 - Buffer Pool Hit Rate(缓冲池命中率):逻辑读有多少比例直接命中内存,而不是去磁盘读页。 - InnoDB 行操作速率(InnoDB 层行读写的频率) - 行锁等待强度:行锁等待次数与等待总时长。 - redo 生成速率 - 脏页比例/flush 压力 - OS 资源层指标 - CPU 与 load - 磁盘 IO - 内存 (swap/page cache) - 网络 体系架构 - mysql 体系架构 - Server 层 - 连接与会话管理 - 客户端连接管理:TCP/Unix Socket,握手认证 - 线程模型:一连接一线程 - 会话上下文:事务隔离级别,临时表,用户变量,prepared statement 等 - SQL 接收与解析 - 词法/语法分析:把 SQL 文本解析成 AST - 预处理:语义检查 - 优化器 - 生成执行计划:选择访问路径、Join 顺序、Join 算法 - 成本估算依赖:统计信息、索引基数、直方图、代价模型 - 典型产物:EXPLAIN 输出 - 执行器 (Executor) - 按执行计划逐步执行 - 调用存储引擎 API 取行,写行 - 负责把结果返回给客户端 - Using filesort、Using temporary 等现象大多发生在执行阶段 - 查询缓存-8.0移除 - 元数据与权限 - Server 日志:binlog(逻辑日志) - binlog 在 Server 层:用于复制(主从)与点时间恢复 - 提交时与 InnoDB redo 通过 2PC 保持一致性 - Storage Engine 层(存储引擎层) - 内存结构 - Buffer Pool:缓存数据页与索引页 - Change Buffer:对二级索引的变更做缓冲 - 磁盘结构 - 表空间:存数据页/索引页 - redo log:WAL,保证崩溃恢复 - undo log:回滚与 MVCC 版本链 - doublewrite buffer:防止部分写导致页损坏 - 索引与访问 - 聚簇索引:PRIMARY KEY 叶子存整行 - 二级索引:叶子存二级键 + 主键值 - 访问路径:范围扫描、点查、回表、覆盖索引 - 事务与 MVCC - 事务隔离:RC/RR/Serializable - MVCC:读视图 + undo 版本链 - 锁:行锁、间隙锁、next-key 锁 - 崩溃恢复 - 依赖 redo:重放已经提交事务对页的修改 - undo:回滚未提交事务 - SELECT 查询典型数据流 - 客户端连接进入 Server 层,会话建立 - Parser 解析 SQL -> AST - Optimizer 基于统计信息选择计划 - Executor 执行计划:通过 Handler 调用 InnoDB 读取行 - InnoDB 在 Buffer Pool 找页 - 结果返回客户端 - 架构图 -  - 事务提交典型数据流 - Executor 调用 InnoDB 写行,更新 buffer pool 中的数据页,产生 undo - 生成 redo WAL,记录页修改 - 提交时 2PC - InnoDB 写 redo prepare - Server 写 binlog - InnoDB 写 redo commit - 后台线程刷脏页到数据文件,不要求提交同步 附录 docker-componse.yml ...