实验元数据 (Meta Data)
实验编号/标题:Transformer 实验
日期:2026-02-23
所属领域/标签:#Transformer #数据结构
耗时:08:32 -
🎯 实验前:假设与目标 (Plan)
当前问题 (Problem):我需要了解 Transformer 的结构
实验目标 (Objective):验证并模拟 Transformer 的底层数据结构
核心假设 (Hypothesis):
🧪 实验中:执行步骤与变量 (Do)
准备工作/工具:
控制变量 (Variable)
执行步骤 (Log):
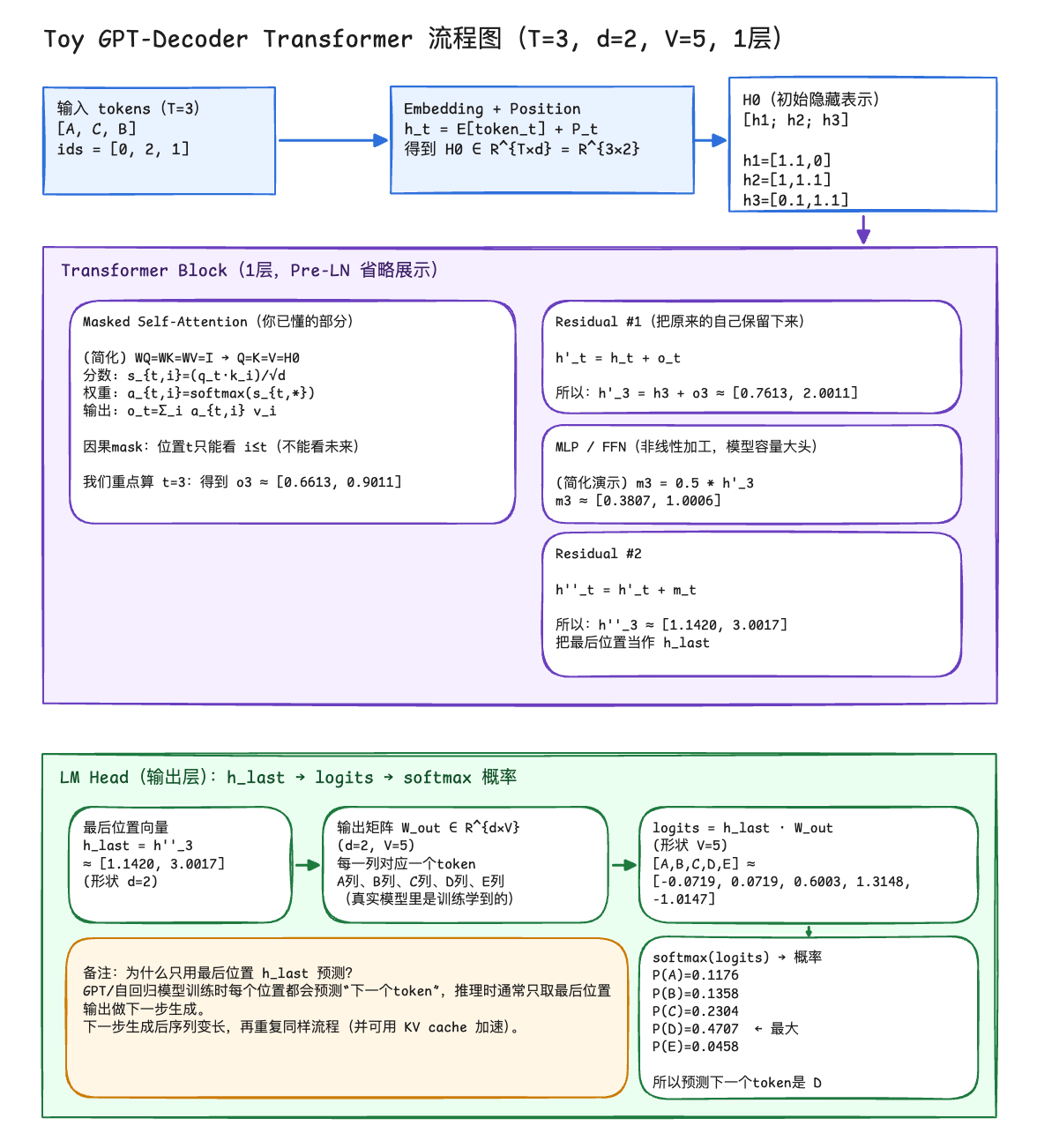
设定:词表、输入、模型参数
词表 V=5,5 个 token
| token | id |
|---|---|
| A | 0 |
| B | 1 |
| C | 2 |
| D | 3 |
| E | 4 |
输入序列 T=3,Prompt 是:A C B,token ids: [0 2 1]
模型看到 A C B 后,下一个 token 最可能是什么。
Embedding + 位置:把 token 变成向量
1.1 Token embedding 每个 token 2 维
embedding 表:
E[A] = [1,0], E[B] = [0, 1], E[C] = [1, 1] E[D] = [-1, 1], E[E] = [0, -1]
1.2 位置向量(每个位置 2 维)
P1 = [0.1,0.0] P2 = [0.0,0.1] P3=[0.1,0.1]
1.3 初始隐藏状态 H0
ht = E[tokent] + Pt
h1 = [1,0] + [0.1,0] = [1.1, 0]
$$ H_0 = \begin{bmatrix} 1.1 & 0 \\ 1 & 1.1 \\ 0.1 & 1.1 \\ \end{bmatrix} $$
一层 Transformer Block:Attention + Residual + MLP + Residual
2.1 Attension
令 $W_Q=W_K=W_V=I$
$Q=K=V=H0$
2.2 位置 3 的 Attention 输出
Step A: 算分数 $s_{3,i} = \frac {q_3\cdot k_i} {\sqrt 2}$
$s_3=[0.0778,0.9269,0.8626]$
mask 对 t=3 不影响,因为 1..3 都允许看。
Step B: softmax 得注意力权重 $a_3$
- exp(0.0778) = 1.0808
- exp(0.9269) = 2.5267
- exp(0.8626) = 2.3693
总和 = 5.9768
权重:
- a_{3,1} = 1.0808/5.9768 = 0.1808
Step C: 加权求和 Value 得输出
$o_3 = \sum_i a_{3,i}v_i = [0.6613,0.9011]$
最后一个 token 的新表示,把历史 token 的信息按权重融合进来
Residual 1: 把 Attention 输出加回去
$$ h3’=h3+o3=[0.7613,2.0011] $$
MLP 在做一次非线性加工
先缩放一半再 ReLu,这里都为正 ReLu 不变
$m_3 = 0.5\cdot h_3’=[0.3807,1.0006]$
Residual2: 把 MLP 输出再加回去
$h_3’’=h_3’+m3=[1.1420,3.0017]$
$h_{last}=[1.1415,3.0015$
输出头 hidden->logits->概率
词表输出矩阵
给每个 token 一个 2 维列向量
A 列: [0.2, -0.1] B 列: [-0.2, 0.1] C 列: [0.0, 0.2] D 列: [0.1, 0.4] E 列: [-0.1, -0.3]
logits 计算 $logits=h_{last}\cdotW_{out}$
对每个 token v, $logit_v = h_{last} \cdot W_{out}^{(v)}$
logits=[-0.0719,0.0719,0.6003,1.3148,-1.0147]
对应 [A,B,C,D,E]
softmax 得到下一 token 的概率
P(A) = 0.1176 P(B) = 0.1358 P(C) = 0.2304 P(D) = 0.4707 P(E) = 0.0458
模型认为下一 token 最可能是 D。
👁️ 实验后:现象与数据 (Check)
🧠 深度复盘:分析与结论 (Act)
Transformer 在做什么
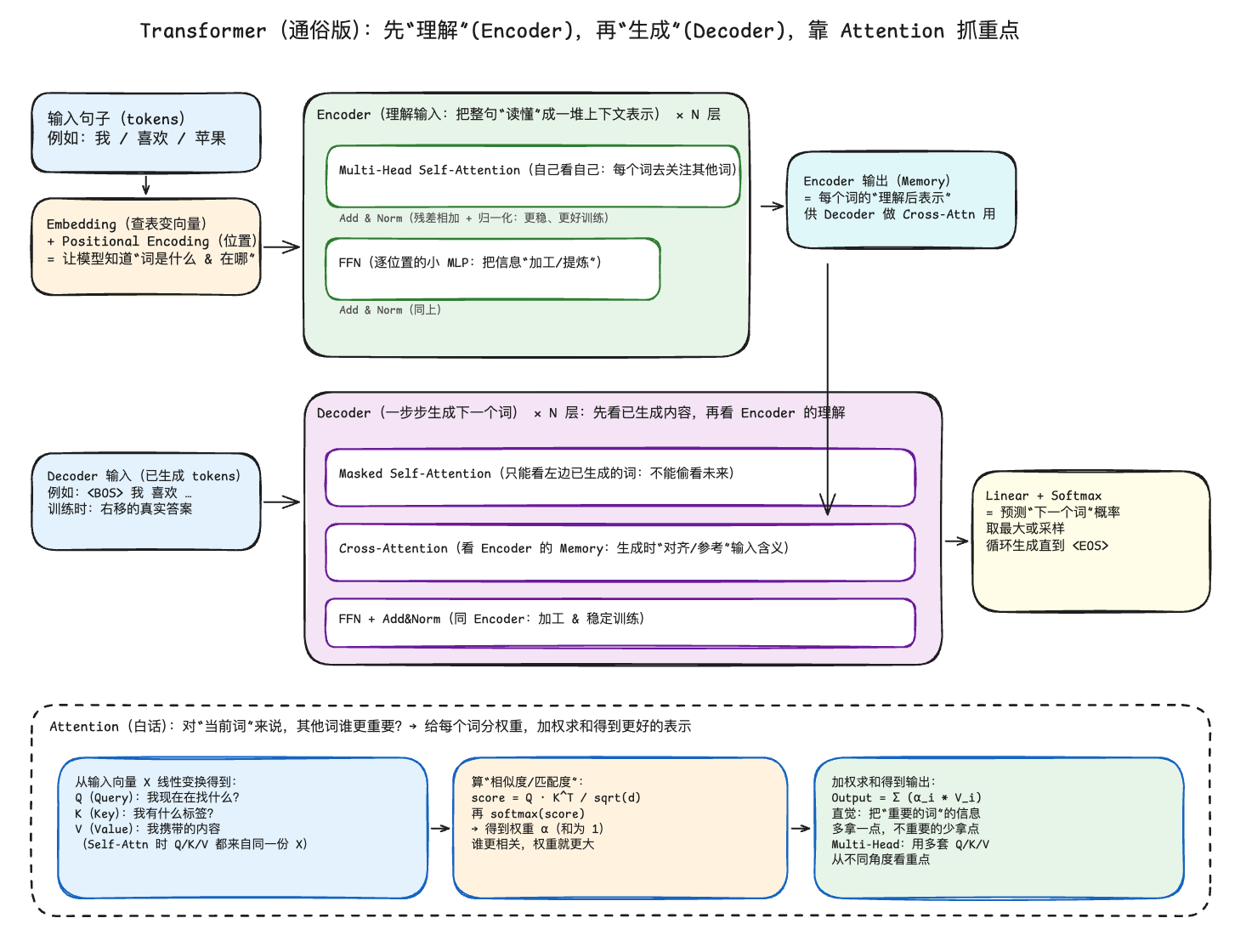
把 Transformer 想象成一个上下文混合器:
- 输入是一串 token。
- 每一层都会让每个 token 去参考别的 token,把重要信息拿过来(Attention)
- 最后模型输出下一个 token 是什么的概率分布
每一层都在做“看全文->挑重点->融合信息->更新表示“。
举例:有一个句子
“小明把苹果给了小红,因为 __ 很饿”
你需要模型知道“很饿”的主语更可能是“小明”(给了苹果所以自己饿)还是“小红”(拿到苹果也可能饿)。
这类指代/语义关联,要靠“看上下文”。
Attention 的工作就是:
让当前这个位置的 token,去上下文里找最相关的 token,把它们的信息融合进来。
Attention 一次计算的过程
假设在处理第 t 个 token,有一个向量表示 $x_t$,来自(embedding + 前几层)
Step1:生成 Q/K/V(三份“同一个 token 的不同用途版本)
对每个 token 的表示 x,分别做三次线性变换:
- $q = x{W_q}$(Query,我想找什么)
- $k = x{W_k}$(Key,我能被怎么匹配)
- $v = x{W_v}$(Value,我真正提供的内容)
用起来的意思是:
- 用 q 去和所有 k 计算相似度,决定该看谁。
- 最后拿到是 v 的加权和,决定“抄什么内容回来“
Q/K 负责找人,V 负责搬运信息。
Step2:算相似度分数(“我和你相关吗?“)
对第 t 个 token 的 query $q_t$,和每个位置 i 的 key $k_i$ 做点积
$$ s_{t,i} = \frac {q_t\cdot k_i}{\sqrt{d}} $$
$s_{t,i}$ 大:说明 t 更想关注 i
除以 $\sqrt d$:让数值别太大,否则 softmax 会变成 0/1,训练不稳
现在得到一排分数:[2.3, 0.1, …]
不是权重,只是偏好分
Step3: softmax 算权重
对一排分数做 softmax:
$$ a_{t,i} = softmax(s_{t,*})_i $$
- 全部权重 >=0
- 权重加起来 = 1
- 分数最大的 token 会得到最大的权重
- 权重就是我抄他信息到比例
Step4:用权重对 V 做加权求和(真正的融合信息)
$$ o_t=\sum_i a_{t,i}v_i $$
第 t 个 token 的新表示 $o_t$ 是从别的 token“按比例抄来的综合信息“。
例子
3 个 token:[小明,给,苹果],假设现在要更新 token 苹果的表示,让它知道苹果是被给出去的东西。
已知(假设算出来的 Q/K/V)
- 对苹果得到 query:$q_{苹果}=[1,0]$
- 三个 token 的 key
- $k_{小明}=[1,0]$
- $k_{给}=[2,0]$
- $k_{苹果}=[0,1]$
- 三个 token 的 value
- $v_{小明}=[10,0]$(代表主体信息)
- $v_{给}=[0,10]$(代表动作信息)
- $v_{苹果}=[1,1]$(自身信息)
算相似度(点积)
用 $q_{苹果}=[1,0]$ 去点积每个 k:
- 和小明:$1\cdot 1+0\cdot 0 = 1$
- 和给:$1\cdot 2 + 0\cdot 0 = 2$
- 和苹果:$1\cdot 0 + 0\cdot 1 = 0$
softmax 得权重
softmax(1,2,0) 大致权重会偏向 2:
- 给最大 -> 权重大, 0.66
- 小明次之,0.24
- 苹果最小,0.1
加权求和 V
$$ o_{苹果} = 0.24[10,0] + 0.66[0,10] + 0.10[1,1] = [2.5,6.7] $$
从输入到输出流水线
Tokenization 把文字变为 token ID
- 文字无法直接进神经网络,需要先变成数字(token ID)
- tokenizer 会把文本切分成小块:可能是字、词、子词。
- 输出是一串整数:[314,25,908,…]
Embedding:把 token ID 变成向量
- tokenId 只有编号,没有语义
- embedding 表就是一个大字典:每个 token 映射到一个向量
- 得到矩阵 X:形状是 [序列长度 T,隐藏维度 d]
- embedding 是把编号变成可计算的语义坐标
Position:告诉模型顺序
Transformer 本身不自带顺序概念 加位置编码:
- 绝对位置:第一个 token、第二个 token
- RoPE(旋转位置编码):更常见,擅长长上下文
下一步行动 (Next Actions):
✅ 验证通过,纳入标准流程。
❓ 产生新问题:验证 Redis ZSet 的底层结构