实验元数据 (Meta Data)
实验编号/标题:Redis set 底层数据结构实验
日期:2026-02-22
所属领域/标签:#Redis #数据结构
耗时:22:20 - 22:42
🎯 实验前:假设与目标 (Plan)
当前问题 (Problem):我需要了解 Redis zset 的底层数据结构
实验目标 (Objective):验证并模拟 Redis zset 的底层结构,查看 Redis 底层代码
核心假设 (Hypothesis):
Redis zset 的值会根据 zset 中元素的个数转换为 listpack 和 quicklist
🧪 实验中:执行步骤与变量 (Do)
准备工作/工具:
| |
配置文件
| |
控制变量 (Variable)
仅基于 List 结构进行实验
执行步骤 (Log):
子实验一:测出 intset
- 添加整数,查看编码

子实验二:测出 listpack
- 添加小集合+非整数元素

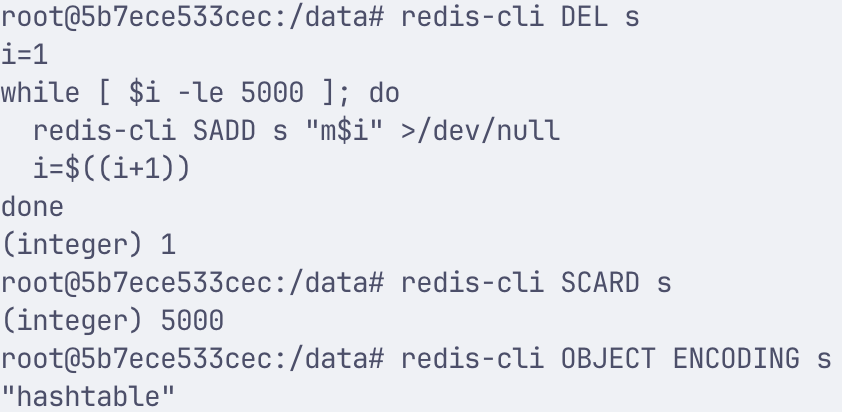
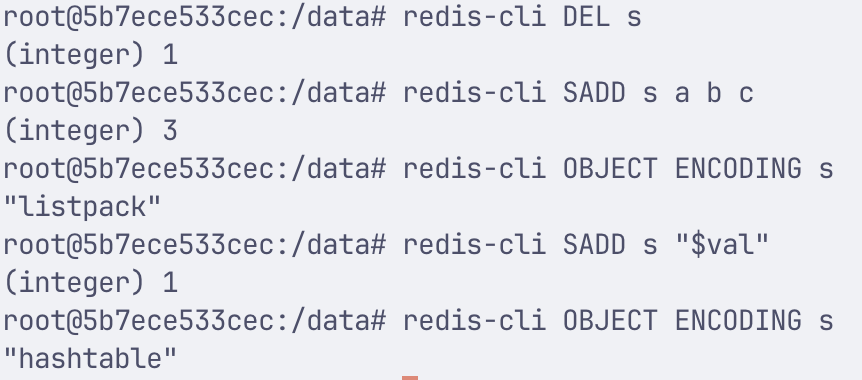
子实验三:转换成 hashtable
- 查看阈值:

- 用很多元素超 set-max-listpack-entries
- 用单个很长的元素超 set-max-listpack-value
👁️ 实验后:现象与数据 (Check)
子实验一:测出 intset
子实验二:测出 listpack
子实验三:转换成 hashtable
🧠 深度复盘:分析与结论 (Act)
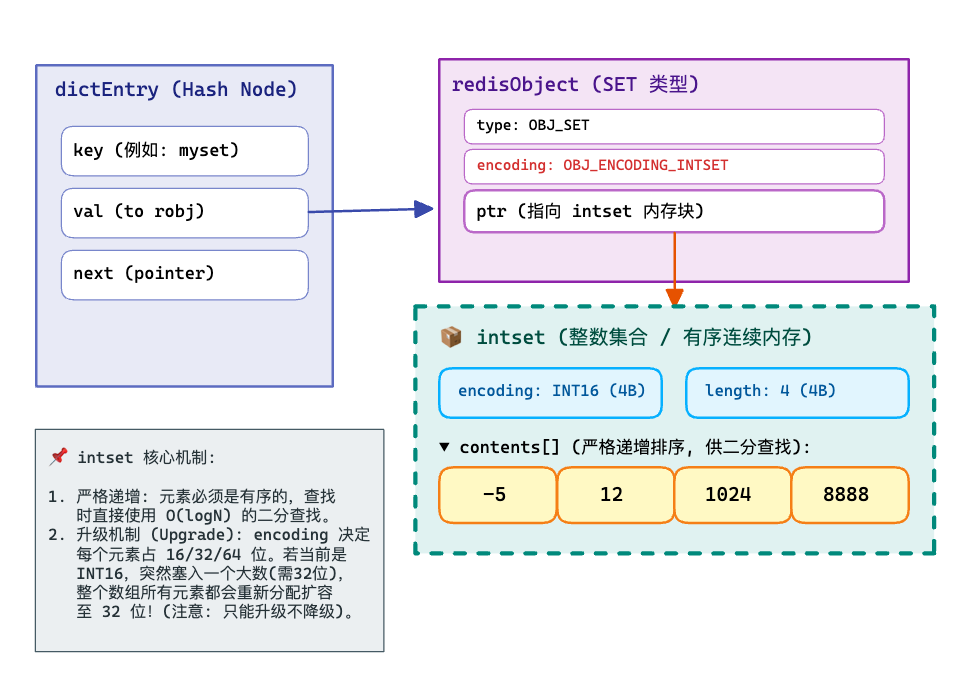
inset 结构
适用条件:
- Set 里所有成员都是整数(可解析为整型)
- 且规模较小(阈值由 set-max-intset-entries 控制;超出会转 hashtable / listpack 等)
结构:
| |
关键特性:
- 连续内存 + 排序:查找用二分(或类似方式),插入需要移动元素(O(n)),但小集合非常省内存。
- 只能存整数;一旦插入非整数成员,就会触发转换(通常到 listpack/hashtable)。
listpack 结构
| |
listpack 的“总字节数/元素个数/结束标记 + N 个条目”的布局在 RDB/内部格式里就是这种结构。
- 非常省内存(无 per-element 指针开销),适合小集合。
- 但因为是顺序紧凑存储:成员查找通常是线性扫描(O(n)),所以只适合小规模;超过阈值会自动转为 hashtable。
hashtable 结构
| |
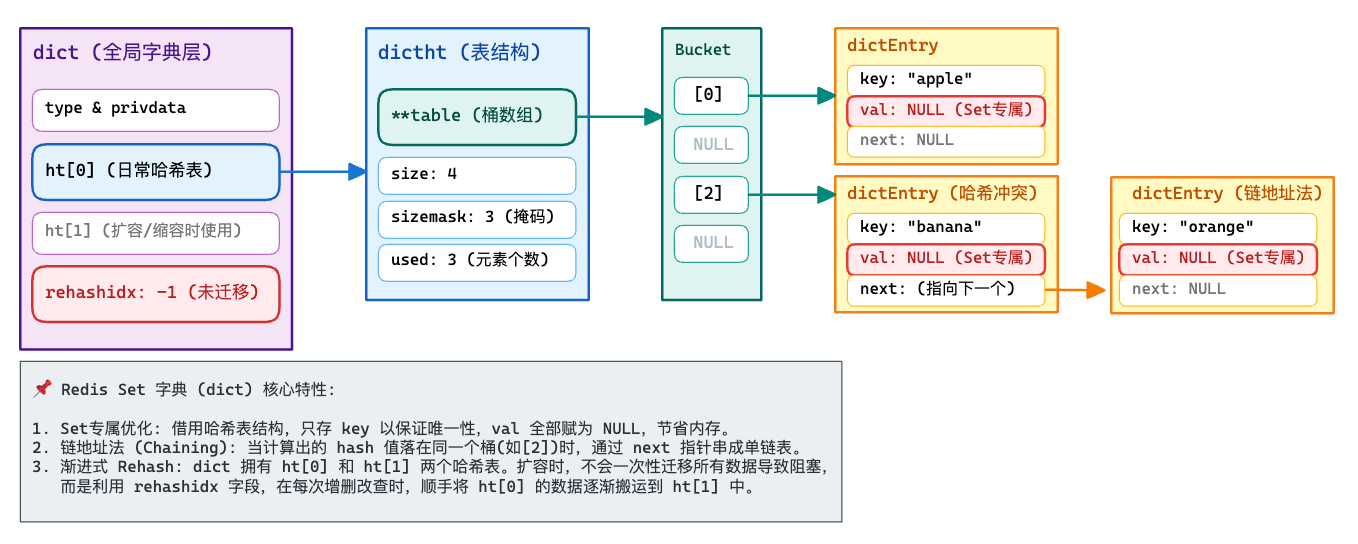
Set 的 dict 用法是:成员作为 key 存在字典里,value 通常是空/固定哑元
- 平均 O(1) 的 SISMEMBER / SADD / SREM(哈希查找)。
- 内存更大(需要 bucket、dictEntry、key 对象等开销),但适合大规模和高性能需求。
- 渐进式 rehash:扩容缩容时不会一次性卡顿(通过 ht[0]/ht[1] 分步搬迁)。
渐进式 rehash
dict 基本结构
Redis 的 dict 不是一张表,而是:
- ht[0]:当前正在用的表(active table)
- ht[1]:rehash 期间的新表(expanding/shrinking table)
- rehashidx:rehash 进度索引;-1 表示没在 rehash;>=0 表示正在把 ht[0] 的 bucket 从这个下标开始搬迁到 ht[1]。
直观图:
- 不在 rehash:只用 ht[0]
- 在 rehash:ht[0] + ht[1] 同时存在,逐步搬 bucket
渐进过程
rehash 不是把所有 key 重新计算后“一次性搬完”,而是每次只搬 一小段 bucket:
- 找到 rehashidx 指向的 bucket
- 把该 bucket 链表上的所有 entry 重新计算 hash,插入到 ht[1] 对应 bucket
- rehashidx++,跳过空 bucket
- 当 ht[0].used == 0:rehash 完成,ht[1] 变成 ht[0],ht[1] 清空,rehashidx = -1
读写正确性
当 dictIsRehashing(d) 为真时:
查找(GET / SISMEMBER / HGET 等):需要在 两张表都查
- 先查 ht[0]
- 找不到再查 ht[1] 因为有些 bucket 已经搬走,有些还在旧表。
插入(SET / SADD / HSET 等):通常直接插到 ht[1](新表),避免新写入又写进旧表导致反复搬。
删除:两边都可能命中(取决于对象是否已搬迁),实现上会按“查找逻辑”定位后删除。
下一步行动 (Next Actions):
✅ 验证通过,纳入标准流程。
❓ 产生新问题:验证 Redis ZSet 的底层结构