用于日后检索和归档,建立知识索引。
实验编号/标题:例如:自动调研 Agent (LangGraph + Plan-And-Execute)
日期:2026-02-24
所属领域/标签:例如:#LLM #Plan-And-Execute
耗时:2小时
🎯 实验前:假设与目标 (Plan)#
实验目标 (Objective):通过构建一个能自主制定调研计划、搜索信息、审查质量并生成报告的 Agent,掌握 LangGraph 状态机、Plan-and-Execute 模式、条件路由、Reflection(自我反思)等 Agent 编排的核心能力。
核心假设 (Hypothesis):(最关键的一步) 我认为怎么做能成功?
构建一个自动调研 Agent,输入一个主题,它能:
- Planner — 自动制定 3-5 步调研计划
- Researcher — 逐步执行搜索,收集信息
- Reviewer — 审查调研质量,决定是否需要补充
- Writer — 将调研结果整理为结构化报告
🧪 实验中:执行步骤与变量 (Do)#
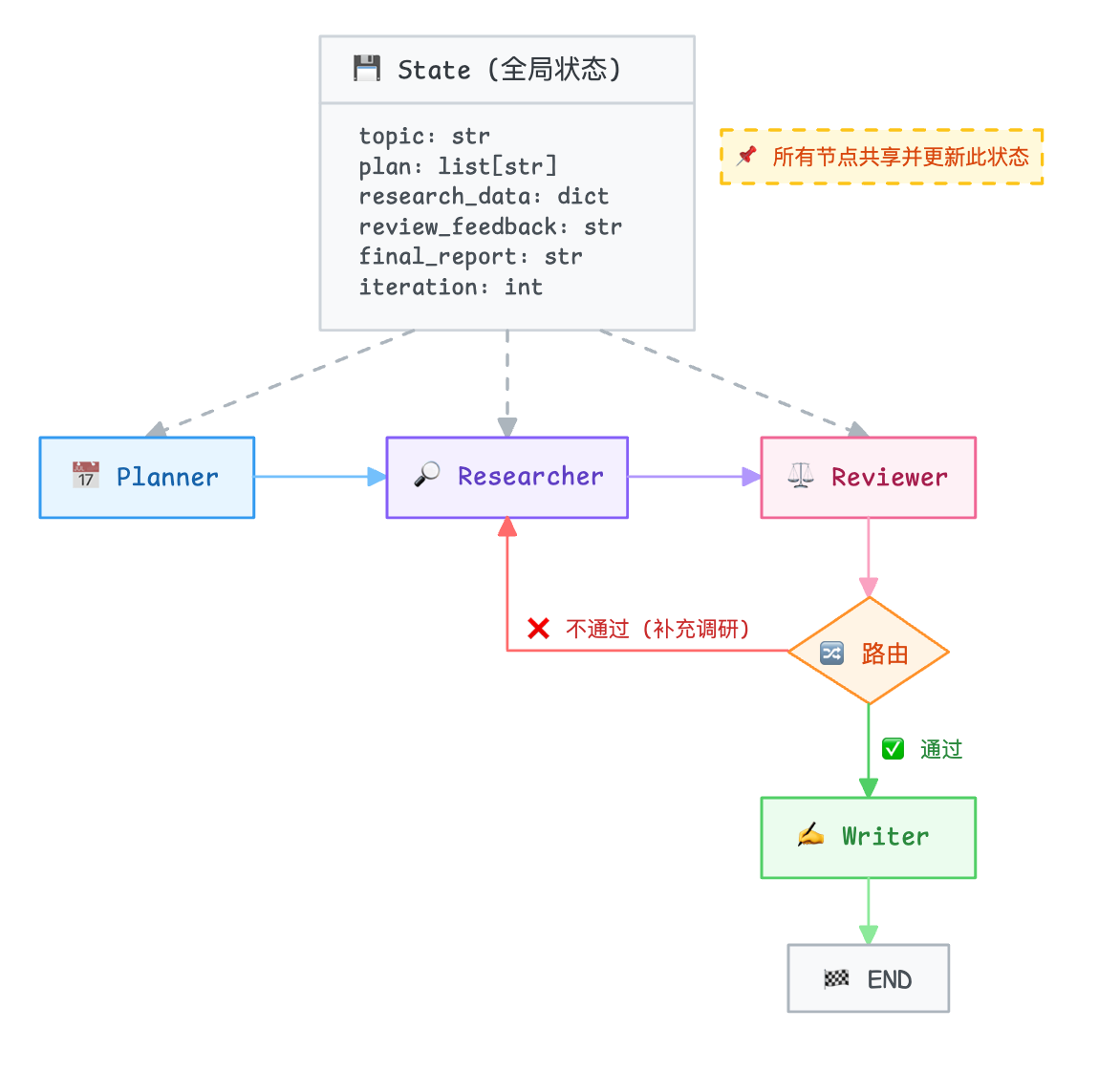
整体架构图#
执行步骤 (Log):#
定义状态#
是 LangGraph 的起点,状态定义了在整个图中流转的数据结构。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
| # src/state.py
from typing import TypedDict
class ResearchState(TypedDict):
"""调研 Agent 的全局状态
LangGraph 的核心概念
- 状态在所有节点间共享
- 每个节点接收当前状态,返回需要更新的字段
- LangGraph 自动合并更新到全局状态
这就像一个在流水线上传递的“工作表”:
每个工位(节点)读取它需要的信息,完成自己的工作后把结果写回去
"""
# 输入
topic: str # 调研主题
# Planner 输出
plan: list[str]
# Researcher 输出
current_step: int # 当前执行到第几个任务
research_data: dict[str, str] # 每个子任务的调研结果 {子任务:结果}
search_queries_used: list[str] # 已使用的搜索关键词(避免重复)
# Reviewer 输出
review_passed: bool # 审查是否通过
review_feedback: str # 审查反馈(如果不通过,说明要补充什么材料)
supplementary_tasks: list[str] # 补充调研任务
# Writer 输出
final_report: str # 最终报告
# 控制流
iteration: int # 当前迭代次数(防止无限循环)
max_iterations: int # 最大迭代次数
errors: list[str] # 错误记录
def create_initial_state(topic: str, max_iterations: int = 3) -> ResearchState:
"""创建初始状态"""
return ResearchState(
topic=topic,
plan=[],
current_step=0,
research_data={},
search_queries_used=[],
review_passed=False,
review_feedback="",
supplementary_tasks=[],
final_report="",
iteration=0,
max_iterations=max_iterations,
errors=[],
)
|
搜索工具#
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| # src/tools.py
from duckduckgo_search import DDGS
def web_search(query: str, max_results: int = 5) -> str:
"""执行网络搜索 — 复用项目 2 的搜索能力
这里把搜索封装为一个纯函数(而非 Tool 类),
因为在 LangGraph 中工具调用方式不同于项目 2 的 ReAct 循环。
"""
try:
with DDGS() as ddgs:
results = list(ddgs.text(query, max_results=max_results))
if not results:
return f"未找到关于 '{query}' 的搜索结果。"
formatted = []
for r in results:
formatted.append(
f"标题: {r['title']}\n"
f"内容: {r['body']}\n"
f"来源: {r['href']}"
)
return "\n\n---\n\n".join(formatted)
except Exception as e:
return f"搜索出错: {str(e)}"
|
Planner 节点#
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
| # src/nodes/planner.py
import json
from anthropic import Anthropic
from src.state import ResearchState
client = Anthropic()
client.base_url = "http://1.95.142.151:3000"
def planner_node(state: ResearchState) -> dict:
"""规划节点 - 根据主题指定调研计划
LangGraph 节点的标准签名
- 输入:当前完整状态
- 输出:需要更新的字段(dict)
- LangGraph 自动将输出合并到状态中
注意:不需要返回整个状态,只返回变化的字段即可
"""
topic = state["topic"]
print(f"\n📋 Planner: 正在为 '{topic}' 制定调研计划...")
response = client.messages.create(
model="claude-sonnet-4-20250514",
max_tokens=1024,
system="""你是一个调研规则专家,根据用户给定的主题,指定一个全面的调研计划。
规则:
1. 计划应该包含 3-5 个子任务
2. 每个子任务应该足够具体,可以通过 1-2 次网络搜索完成
3. 子任务之间应互不重叠,共同覆盖主题的各个方面
4. 按逻辑顺序排列(如先了解背景,再深入细节)
只返回 JSON 数组格式,不要其他内容
["子任务1描述","子任务2描述","子任务3描述"]""",
messages=[{
"role": "user",
"content": f"请为以下主题指定调研计划:\n\n{topic}"
}],
)
raw = response.content[0].text.strip()
# 解析 JSON
try:
# 处理可能的 markdown 包裹
if "```" in raw:
raw = raw.split("```json")[-1].split("```")[0].strip()
if not raw:
raw = response.content[0].text.strip()
raw = raw.split("```")[-2].strip()
plan = json.loads(raw)
except json.JSONDecodeError:
# 解析失败时用备用方案
plan = [
f"{topic} 的背景和定义",
f"{topic} 的最新发展",
f"{topic} 的关键参与者和产品",
f"{topic} 的未来趋势和影响",
]
print(f" ⚠️ 计划解析失败,使用默认计划")
print(f" ✅ 调研计划({len(plan)} 个子任务):")
for i, task in enumerate(plan, 1):
print(f" {i}. {task}")
# 返回需要更新的字段
return {
"plan": plan,
"current_step": 0,
}
|
Researcher 节点#
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
| import json
from anthropic import Anthropic
from src.state import ResearchState
from src.tools import web_search
client = Anthropic()
client.base_url = "http://1.95.142.151:3000"
def researcher_node(state: ResearchState) -> dict:
"""调研节点 - 逐个执行子任务的搜索和信息收集
这个节点每次只执行一个子任务。
图的条件路由会决定是否还需要继续执行下一个子任务。
每次只做一步的设计让:
1. 状态更新更细粒度
2. 可以在任意步骤插入人工审核
3. 出错时只需重试单个步骤
"""
plan = state["plan"]
current_step = state["current_step"]
research_data = dict(state["research_data"])
# 判断当前执行的是正常计划还是补充任务
supplementary = state.get("supplementary_tasks", [])
if current_step < len(plan):
# 执行正常计划中的子任务
task = plan[current_step]
task_label = f"子任务 {current_step + 1}/{len(plan)}"
elif supplementary:
# 执行补充任务
sup_index = current_step - len(plan)
if sup_index < len(supplementary):
task = supplementary[sup_index]
task_label = f"补充任务 {sup_index + 1}/{len(supplementary)}"
else:
# 所有任务都已经完成
return {"current_step": current_step}
else:
return {"current_step": current_step}
print(f"\n🔍 Researcher: 正在执行 {task_label}")
print(f" 任务: {task}")
# Step 1: 让 LLM 生成搜索关键词
keyword_response = client.messages.create(
model="claude-sonnet-4-20250514",
max_tokens=200,
system="根据调研子任务,生成 2-3 个精准的搜索关键词,返回 JSON 数组格式:[\"关键词1\",\"关键词2\"]",
messages=[{
"role": "user",
"content": f"主题: {state['topic']}\n子任务: {task}"
}],
)
try:
raw = keyword_response.content[0].text.strip()
if "```" in raw:
raw = raw.split("```json")[-1].split("```")[0].strip()
if not raw:
raw = keyword_response.content[0].text.strip()
raw = raw.split("```")[-2].strip()
keywords = json.loads(raw)
except json.JSONDecodeError:
keywords = [task] # 解析失败时直接用任务描述搜索
print(f" 🔑 搜索关键词: {keywords}")
# Step 2: 执行搜索
all_search_results = []
queries_used = list(state.get("search_queries_used", []))
for keyword in keywords:
if keyword in queries_used:
print(f" ⏭️ 跳过重复搜索: {keyword}")
continue
result = web_search(keyword, max_results=3)
all_search_results.append(f"搜索 '{keyword}' 的结果:\n{result}")
queries_used.remove(keyword)
combined_results = "\n\n===\n\n".join(all_search_results)
# Step 3: 让 LLM 总结搜索结果
summary_response = client.messages.create(
model="claude-sonnet-4-20250514",
max_tokens=1024,
system="""你是一个调研助手。根据搜索结果,为指定的子任务提取关键信息并总结。
规则:
1. 只提取与子任务直接相关的信息
2. 标注信息来源(哪个搜索结果)
3. 如果搜索结果信息不足,说明缺少什么
4. 用简洁的要点形式总结""",
messages=[{
"role": "user",
"content": f"子任务:{task}\n\n搜索结果:\n{combined_results}"
}],
)
summary = summary_response.content[0].text
research_data[task] = summary
print(f" ✅ 已完成: {task[:50]}...")
return {
"research_data": research_data,
"current_step": current_step + 1,
"search_queries_used": queries_used,
}
|
Reviewer 节点#
👁️ 实验后:现象与数据 (Check)#
客观记录发生了什么,不要带主观评价。
观察到的现象:
成功了吗?报错了吗?报错信息是什么?
产出物的样子(附截图/照片)。
关键数据:
耗时、准确率、转化率、温度、分数等。
例:前5页成功,第6页开始报错 403 Forbidden。
🧠 深度复盘:分析与结论 (Act)#
为什么需要 LangGraph#
LangGraph 用图来建模 Agent 工作流:
- 节点(Node)=一个处理步骤(例如“指定计划“,“执行搜索“)
- 边(Edge)=步骤之间的连接
- 条件边 = 根据运行时状态决定走向哪个节点
- 状态(State)=在所有节点之间共享的数据
PlanAndExecute vs ReAct#
下一步行动 (Next Actions):#
✅ 验证通过,纳入标准流程。
🔄 验证失败,修改假设,开启下一次实验(EXP-002)。
❓ 产生新问题:[记录新问题]